Machine Learning and ML Model?
ML is the process of training a Machine Learning model, to make useful predictions or generate content (like text, images, audio, or video) from data.
Types of Machine Learning
| Supervised Learning | Unsupervised Learning | Semisupervised Learning | Reinforcement learning | Generative AI | |
|---|---|---|---|---|---|
| What |
Training data feed to the algorithm includes the desired
solutions(called labels). Example: This is like a student learning new material by studying old exams that contain both questions and answers |
Dataset does not have labels. ML model tries to learn without teacher. ML has to estimate whether it's correct/incorrect and create its own rules |
lot of unlabeled data and a little bit of labeled data. Examples: 1. FB Photos: When we load photos, we provide labels to few and leave others. AI identifies photos. |
Agent(AI Program) can observe the environment, select and perform
actions, and get rewards or penalties based on actions performed
within an environment Example: used to train robots to perform tasks, like walking around a room |
Models that creates content from user input. Eg: Create unique images, music compositions, jokes, Text-to-text Text-to-image Text-to-video Text-to-code Text-to-speech Image and text-to-image |
| Types |
1. Classification (give yes/no): Example a. Spam Filterning: Algo is trained with many example emails along with their class (spam or ham). Each email has a label. Types of classification models: 1. Binary classification: Model output a value from a class that contains only two values, for example rain or no rain 2. Multiclass classification: Output a value from a class that contains more than 2 values. Eg: rain, hail, snow, or sleet 2. Regression: (give % or numeric value): Predict whether based on inputs, Predict price of car provided with some inputs(mileage, age, brand, etc.) 3. Logistic Regression (yes/no with %): Mix of classfication & Regression. Example: 20% of chances being a spam. |
1. Clustering: The model finds data points that demarcate natural groupings. 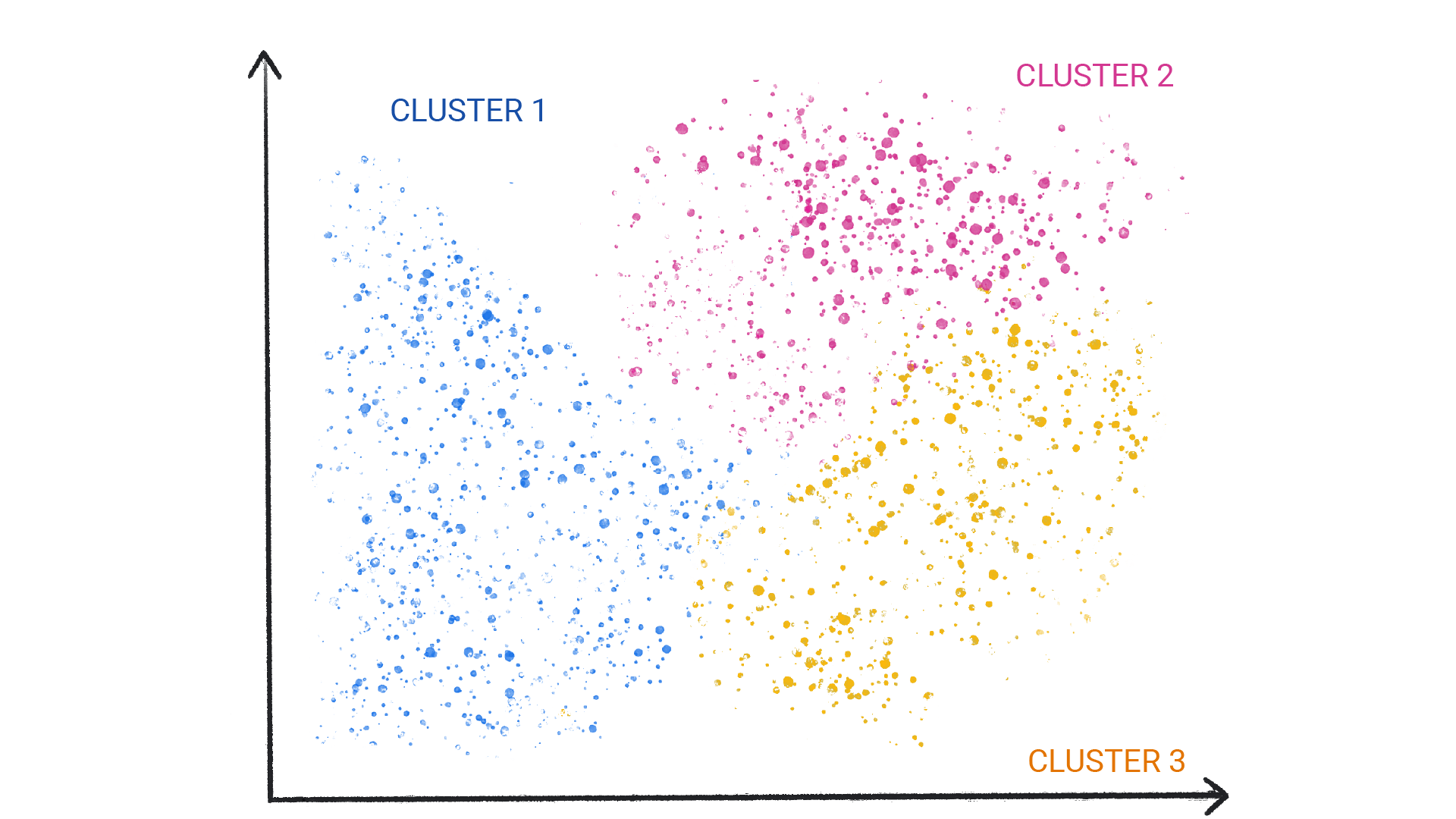
Algorithms used: k-Means Hierarchical Cluster Analysis (HCA) Expectation Maximization 2. Visualization and dimensionality reduction With unlabelled data this algorithm provides ouput which can be plotted on 2-D, 3-D plane. Algorithms used: Principal Component Analysis (PCA) Kernel PCA Locally-Linear Embedding (LLE) t-distributed Stochastic Neighbor Embedding (t-SNE) 3. Association rule learning: This provides output as relations between attributes. Algorithms used: Apriori Eclat |
|||
| Algorithms |
k-Nearest Neighbors Linear Regression Logistic Regression Support Vector Machines (SVMs) Decision Trees & Random Forests Neural networks |
Clustering: k-Means, Hierarchical Cluster Analysis (HCA),
Expectation Maximization Visualization and dimensionality reduction: Principal Component Analysis (PCA), Kernel PCA, Locally-Linear Embedding (LLE), t-distributed Stochastic Neighbor Embedding (t-SNE) Association rule learning: Apriori, Eclat |
Deep belief networks (DBNs) |
Supervised Learning Models
-
Machine Learning model is a Algorithm, which makes predictions after
getting trained on data
Supervised Learning:
Regression: Decision Tree Regressor
Classification: Decision Tree Classifier
Regression
Decision Tree Regressor
-
This is Binary Tree(not balanced) which works in flowchart-like manner
where each internal node represents a "test" on an attribute, each
branch represents the outcome of the test, and each leaf node represents
numerical value (ie Prediction).
How it works? Predicting Whether a Customer Will Buy a Product Using Two Decision Trees
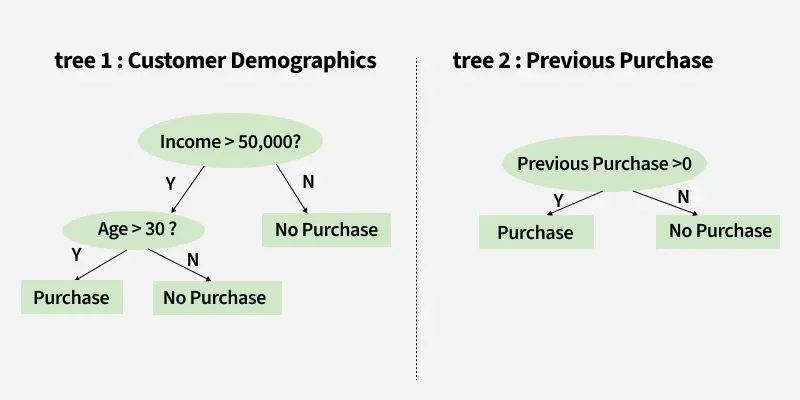
|
If Tree 1 predicts "Purchase" and Tree 2 predicts "No Purchase", the final prediction might be "Purchase" or "No Purchase" depending on the weight or confidence assigned to each tree. |
Information Gain tells us how useful a question (or feature) is for splitting data into groups
It measures how much the uncertainty decreases after the split.
For example if we split a dataset of people into "Young" and "Old" based on age and all young people bought the product while all old people did not, the Information Gain would be high
Gini Index in Decision Tree: Metric to measure how often a randomly chosen element would be incorrectly identified. Lower Gini index represents a better split
Fitting
Overfitting in Decision Tree
when tree has too many splits becomes too deep, and it makes very good predictions to training data, but does poor predictions on new data.
As the tree gets deeper, the dataset gets sliced up into leaves with fewer choices. we'll have 210 groups by the time we get to the 10th level. That's 1024 leaves.
When we divide the tree in too many leaves, we also have fewer data in each leaf. Very few Leaves will make predictions that are quite close to actual values, but they may make very unreliable predictions for new data (because each prediction is based on only a few input samples).
Underfitting in Decision Tree
On otherside, if only few splits are performed(only 2 or 4), Resulting predictions may be far off for most input samples, even in the training data.
When a model fails to capture important distinctions and patterns in the data, & perform poorly even in training data, poorly in new data is underfitting
Overfitting or underfitting(What's preferred)? We need to hit a sweet spot between 2
Random Forest Regressor
-
Problems with Decision Tree:
Overfitting(Deep tree with lot of leaves) or underfitting(very
less depth) Random forest solves it
What is Random Forest?
Random forest uses lot of decision trees & make prediction by averaging each of Component trees.
Has much better predictive accuracy than a single decision tree & works well with default params