CUDA(Compute Unified Device Architecture)
-
This is parallel computing platform and programming model created by NVIDIA.
It leverages the parallel compute engine in NVIDIA GPUs to solve many complex computational problems
CUDA comes with a software environment that allows developers to use C++ as a high-level programming language.
CUDA Programming Model
Concepts
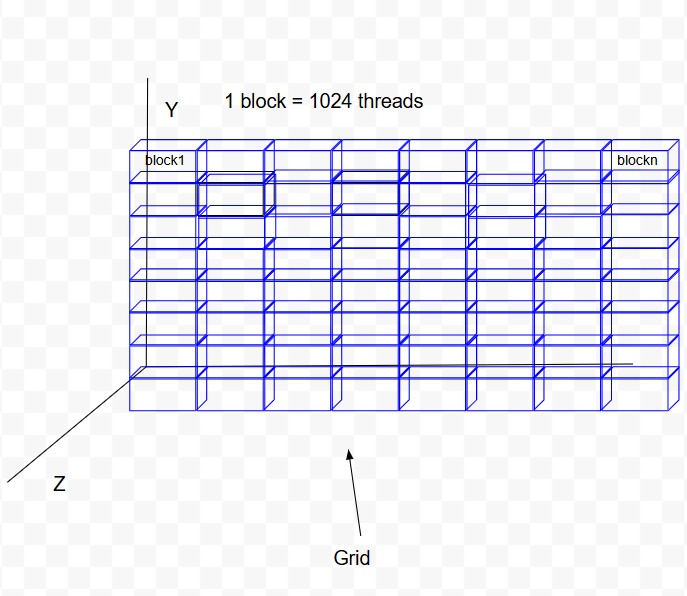
Grid, Block, Threads
| Term | Meaning | ||
|---|---|---|---|
| Thread |
Smallest unit of execution in CUDA Thread within same Block runs same code but with different data (data parallelism) Each thread is identified using thread index (threadIdx.x, threadIdx.y, threadIdx.z). |
||
| Block |
1 block can have 1024 threads at most Threads in a block can communicate with each other through shared memory A group of threads that execute on the same Streaming Multiprocessor (SM) on the GPU are on same block |
||
| Grid |
Collection of blocks that execute a kernel
|
||
| Thread Block Cluster |
A Thread Block Cluster (or simply Cluster) is a feature introduced in NVIDIA’s Hopper architecture
(e.g., H100 GPU, Compute Capability 9.0) and later. This is group of thread blocks which are scheduled to run together on a GPU Processing Cluster (GPC) Advantage is: Clusters allow blocks within the same cluster to share resources and synchronize, Remember that blocks in different clusters cannot communicate directly. |
Kernel
-
Kernels are the functions that run on the GPU. They are executed in parallel by multiple threads.
These functions are called from the host (CPU) and executed in parallel on GPUs
A kernel is defined using the __global__ declaration specifier
Number of CUDA threads that execute that kernel is given using <<<blocks, threads>>> syntax.
Each thread that executes the kernel is given a unique thread ID that is accessible within the kernel through built-in variables.
/*
__global__ : This is kernel function
Parameters:
A,B,C: Pointers to floating point arrays stored on GPU global memory.
A,B: input arrays. C: OUtput array where sum of A & B is stored.
*/
__global__ void VecAdd(float* A, float* B, float* C)
{
/*
threadIdx {x,y,z} This is a built-in CUDA variable that gives the unique ID of the thread within the block.
threadIdx.x: x position of the thread in the block.
Thread0, x=0. C[0] = A[0] + B[0]
Thread1, x=1. C[1] = A[1] + B[1]
*/
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
/*
<<>>
<<<1, N>>> means there will be 1 block with N threads.
N: Set somewhere before in code
if the arrays have 1024 elements, we can set N = 1024 so that each thread processes one element of the arrays.
*/
VecAdd<<<1, N>>>(A, B, C);
...
}
Inter Thread Communication
1. Threads within the Same Block
-
Threads in the same block can communicate using shared memory
Synchronization within a block is achieved using __syncthreads()
2. Threads in Different Blocks
-
There is no built-in synchronization mechanism across blocks within a kernel (like __syncthreads())
Workarounds for Inter-Block Communication:
Global Memory: Threads in different blocks can write to and read from global memory (e.g., the arrays A, B, C in the code).
Atomic Operations: Use atomic functions to ensure that updates to global memory are done safely.
Multiple Kernel Launches: If inter-block communication is needed, you can launch multiple kernels sequentially, where the output of one kernel serves as the input to the next
Memory Hierarchy
-
Memory available with each thread:
1. private local memory
2. Shared memory in block(lifetime of block)
3.
How many threads GPU can have?
-
Maximum grid dimensions (2³¹ - 1 for x, 65,535 for y and z)
Maximum threads per block (1024)
65535 x 1024 = 67 Million threads per grid.
Theoretically billions of threads per kernel launch
Example
Vector Addition on GPU
Launching a kernel Managing GPU memory Parallelizing a simple computation |
Huge matrix operations for tranining neural networks Image processing Cryptography Bug data processing How to decide on Number of threads to use? In problem on left side, we used 512 threads. Common choices are 256, 512, or 1024 threads per block, as they are multiples of the warp size (32 threads), which is the unit of execution on NVIDIA GPUs. Threads/block depends on problem size and the GPU architecture. How to decide on Number of blocks to use? Based on number of threads needed blocks = ceil(total_elements(=512 in problem on left) / threads_per_block) |
Streaming Multiprocessor (SM)
-
SM is responsible for executing threads in parallel.
Each SM contains multiple CUDA cores (for arithmetic operations), load/store units, special function units
SMs execute thread blocks assigned to them by the CUDA runtime.
Example: NVIDIA A100 GPU (Ampere architecture) has 108 SMs, each with 64 CUDA cores. Each SM can handle up to 2,048 threads concurrently.
- Does the GPU Have as Many SMs as Blocks?
SMs: A fixed hardware resource on the GPU (e.g., 108 SMs on an A100).
Relation b/w Blocks and SMs:
CUDA runtime schedules blocks to available SMs. Each SM can execute multiple blocks concurrently, up to resource limits
If there are more blocks than SMs, the GPU schedules blocks in waves.
Graphics Processing Clusters (GPCs)
-
GPC is primarily used in the GPU’s graphics pipeline (e.g., for rendering tasks in gaming or visualization)
1 GPC = Multiple SMs + raster engines + Texture processing clusters (TPCs)
-
NVIDIA A100 GPU has 8 GPCs, each with 13~14 SMs
GPU
├── GPC 0
│ ├── SM 0
│ │ ├── CUDA Cores (e.g., 64 cores)
│ │ ├── Shared Memory
│ │ ├── Registers
│ │ ├── Warp Schedulers
│ │ ├── Load/Store Units
│ │ ├── Thread Blocks (e.g., Block 0, Block 1)
│ │ │ ├── Threads (0,0,0), (1,0,0), ..., (threadIdx.x, y, z)
│ ├── SM 1
│ ├── ...
│ ├── SM n (e.g., 12 SMs per GPC)
│ ├── Texture Processing Cluster (TPC)
│ ├── Raster Engine
├── GPC 1
│ ├── SMs, TPCs, etc.
├── ...
├── GPC m (e.g., 8 GPCs in A100)
├── Global Memory (HBM/GDDR)
├── L2 Cache
├── Memory Controllers