Partitioning/Sharding(MongoDB,ElasticSearch) / Region(HBase) / Bigtable(Tablet) / vNode(Cassandra) / vBucket(CouchBase)
-
Sharding separates large databases into smaller, more easily managed
parts called shards
Each shard shares the same schema, though the actual data on each shard is unique to the shard.
-
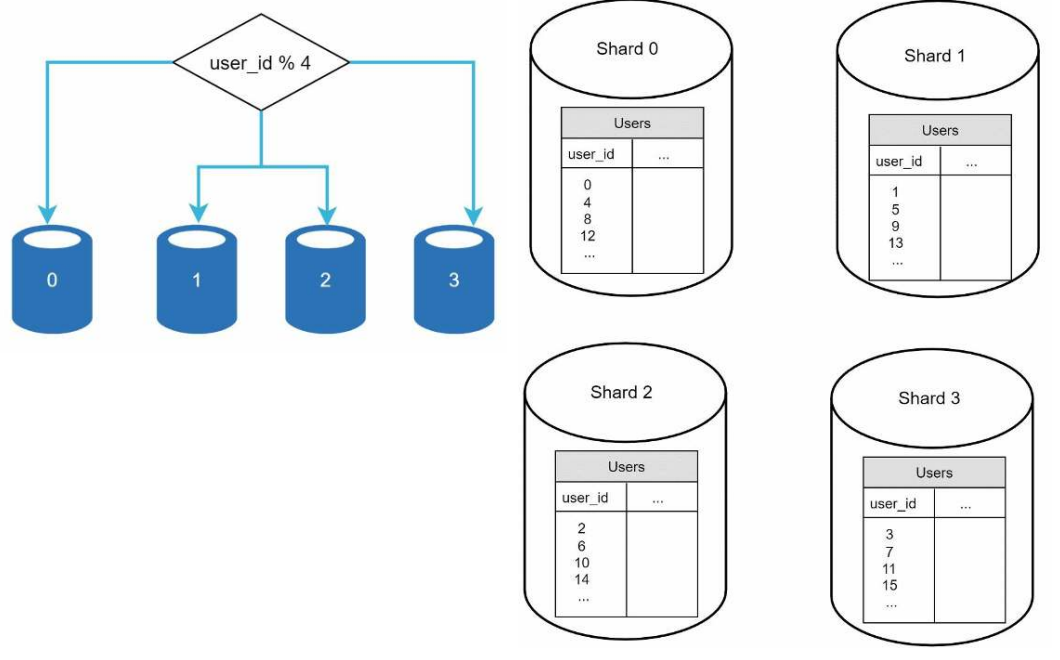
Sharding key/Partition key:
Example: User data is allocated to a database server based on user IDs, a hash function is used to find the corresponding shard.
Determine how data is distributed. In this example (key = user_id % 4)
Criteria is to choose a key that can evenly distributed data
When to use Sharding
-
1. Huge data stored in DB: if data stored in DB is so huge that
i exceeds capacity of DB server
2. High traffic to application: Application experience high query loads, sharding will balance the load across multiple database instances
How App Server interacts with shards
-
1. Direct Requests: Application calculates which shard to query
based on a predefined sharding key(Hash e.g., user ID, geographic
location). Application must implement logic to route requests to the
appropriate shard.
2. via Load Balancer(Not Used/recommended): Application itself handles routing requests to the correct shard based on the sharding key
Issues/Complexities in Sharding
1. Resharding
-
Resharding means redistributing the data among shards.
Why it is needed:
Certain shards might experience shard exhaustion faster than others due to uneven data distribution
How to achieve resharding
1. Update the sharding function to move data around.
2. Consistent Hashing
2. Celebrity Problem (Hotspot key problem)
-
Excessive access to a specific shard could cause server overload.
Imagine data for Katy Perry, Justin Bieber, and Lady Gaga all end up on the same shard
How to Solve? Allocate a shard for each celebrity. Each shard might even require further partition
3. Join and de-normalization
-
Once a database has been sharded across multiple servers, it is hard
to perform join operations across database shards.
How Partioning achieves Scalabilty
-
- Different partitions can be placed on different nodes hence a large
dataset is distributed across many disks, and the query load can be
distributed across many machines/processors.
- With partitioning we speard query load evenly across nodes. That means 10 nodes should be able to handle 10 times read & write throughput wrt 1 node.
Sharding with Replication
- if master/slave replication is used with partitioning, Each node may be master for 1 dataset while slave for other
| Node-1 | | Node-2 |
|partition1 partition2 partition3| |partition3 partition2 partition1|
| (master) (slave) (slave) | | (master) (slave) (slave) |
Types of Sharding
- 1. By Key range
|Partition-1| |Partition-2| |Partition-3|
keys |a-e | |f-o | |p-z |
Advantage: Keys can be kept in sorted order inside the partition.
Disadvantage: Certain types of keys can turn partition into Hotspot. Eg: if a shard stores all tweets of a celebrity user
- 2. By Hash of Keys
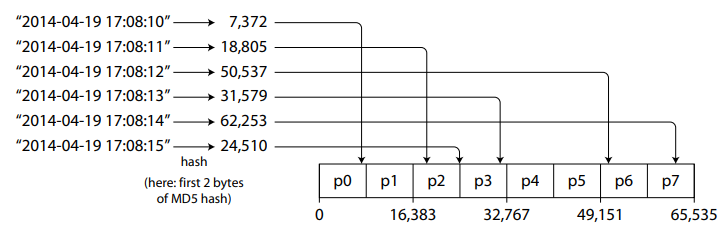
key -> |Hash Function| -> Hash of Shard
Adv: Similar keys different hashes are generated, hence hotspots are avoided.
Disadv:
1. Range based key search property is lost. ie Advantage of Partitioning by Key range is lost.
2. Hotspots still exists: In extreme conditions, where keys differ by millisec, same hash gets generated and all load goes to same shard.
- 3. By reverse indexing/secondary indexes
-
4. Region based Partition / Sharding based on location IDs
Advantages:
1. Data Localization: Users in a particular region primarily access data relevant to that region, which can reduce latency and improve response times.
2. Scaling: By partitioning the database based on region, we can scale system horizontally.
3. Regulatory Compliance: Data privacy laws may require certain data to be stored within specific geographic regions
4. Disaster Recovery: In the event of a localized failure or disaster, having region-based partitions can make it easier to implement disaster recovery strategies. We can focus on recovering data for specific regions without affecting the entire system
5. Reduced Maintenance Downtime: When need to perform maintenance tasks, such as database upgrades, we can target specific regions, minimizing the impact on the overall system.