Microservices Design Patterns
-
These are software patterns that create reusable, autonomous services
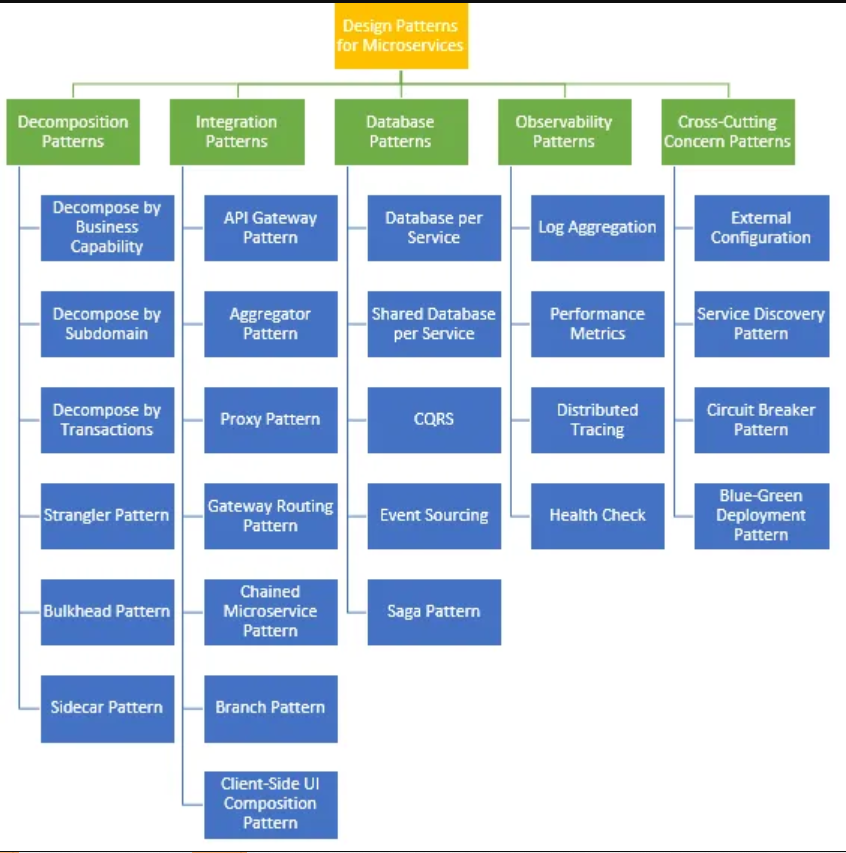
| Pattern Name | Description | Example |
|---|---|---|
| 1. API Gateway |
Single entry point for clients to access multiple microservices.
Client will hit APIs and rest of services sit behind API gateway. Useful for routing, authentication, rate limiting, and other cross-cutting concerns. |
Netflix |
| 2. Service Discovery Pattern | Enables a service client(such as an API gateway), to determine the network location of a service instance so that it can invoke it. | zookeeper |
| 3. Circuit Breaker Pattern | Service1 makes call to Service2. And Service2 is in failure state, instead of keep on trying again and again, Calls to Service2 are stopped after x attempts for n number of seconds. | SRX Config pushed to ConfigPusher and waiting for ACK |
| 4. Externalized Configuration | Configuration settings should be externalized from the codebase, allowing services to be more configurable without requiring redeployment. | ArgoCD manifests, Spring Cloud Config |
| 5. Event-Driven Architecture | Microservices can communicate asynchronously using events | Kafka producer consumer |
| 6. Saga Pattern | A DB transaction is broken into smaller transactions & each transaction is handled by seperate service. |
e-commerce order. Reserve the product. Charge the customer’s card. Reduce the stock Ship the product |
| 7. CQRS (Command Query Responsibility Segregation) |
Responsibility of quering data and handling/processing data is
handled by different components This pattern splits the responsibility of handling commands from retrieving data. |
e-commerce platforms |
Circuit Breaker Design Pattern
-
Suppose service1 gets some data from service2. But there is always the
possibility that the other service2 is unavailable/dead.
When service2 is dead, service1's thread might be pooling service2 to respond. This is resource wastage for service1
Failure to get data can potentially cascade to other services throughout the application, if other services depends on service1.
Problem:
-
How service1 knows quickly that service2 is dead and donot waste its
resources?
Solution:
-
Traditional, Preconfigured thresholds and timeouts
When the number of consecutive failures crosses a threshold stop sending requests for x=10 timeout.
After 10s send only 5 test requests(ie limited number of test requests). If those requests succeed resumes to normal operation. Otherwise, if there is a failure the timeout period begins again.
Modern Adaptive techniques
Using AI and ML dynamically adjust thresholds based on real-time traffic patterns, anomalies, and historical failure rates. This approach improves resiliency and efficiency.
HTTP CLIENT
|
1. Start healthcheck service in thread 2. Check HTTP Server is up and running if state=open, and time elapsed since last failure is greater than our configured restTimeOut. ie we donot want to send ping probes before restIntervalBetweenFailedAttempts Send HTTP GET to endpoint if response was Success, increment success count, make failure count=0 if response was failure, increament failure count and if count > threshold declare failed. HTTP SERVER |